How players reveal themselves in the numbers — proving it, detecting it, and using it
AI-generated image
The Idea: The Draw Is Random, The Players Are Not
Every serious lottery analysis begins with an uncomfortable truth: the draw is random and independent, so nothing you do changes your probability of winning. That wall is real. But there is a crack in it that has nothing to do with the draw and everything to do with the people holding tickets.
Lottery players do not choose their numbers randomly. They pick birthdays, lucky numbers, neat sequences, and shapes traced on the bet slip. This is called conscious selection, a term introduced by Cook and Clotfelter (1993). Because most lottery prizes are pari-mutuel — each prize tier is split among everyone who matched it — conscious selection has a direct financial consequence. If you win with a combination thousands of others also chose, you split the prize into thousands of pieces. If you win with a combination almost nobody chose, you keep far more of it.
So conscious selection creates a genuine, exploitable edge — not over the draw, but over the crowd. The rest of this article explains how the phenomenon was proven academically, how you can prove it for any lottery from public data, how to flag which combinations are “popular,” and — crucially — how to keep that flag honest by measuring exactly how much each rule cuts.
How the Academic Work Proves It
The key reference is Baker and McHale (2011, Journal of the Royal Statistical Society A), “Investigating the behavioural characteristics of lottery players by using a combination preference model.” Their proof is elegant precisely because lottery operators almost never release data on which combinations players chose — they guard it, in one author’s phrase, like a poker player with a royal flush. So the behaviour must be inferred indirectly, from data that is public: the number of winners at each prize tier in each draw.
The argument runs in three steps.
Step one — the random null. If everyone picked randomly, the number of winners at a given tier would follow a Poisson distribution, whose defining property is that its variance equals its mean. Winner counts at different tiers would also be uncorrelated. This is the baseline of “no conscious selection.”
Step two — the data refuses to fit. Real winner counts show two unmistakable departures from Poisson. First, overdispersion: the variance is far larger than the mean, producing long-tailed distributions. Occasionally a hugely popular combination is drawn and the winner count explodes — the paper cites a Canadian draw where a random model predicted about 2.83 winners of a tier but 239 appeared, because thousands had played a clustered sequence. Second, the winner counts across tiers are strongly correlated, which a random model forbids. Both effects are the fingerprint of players piling onto the same combinations.
Step three — a model that reproduces the fingerprint. Baker and McHale build a three-parameter combination-preference model: combinations are ordered, grouped into clusters of similar combinations, and given uneven selection probabilities, with parameters λ (strength of conscious selection), c (number of clusters), and f (fraction of players who pick randomly). Fitted to UK and Spanish data, it reproduces the long tails and correlations that simpler models could not. Their headline estimate: only about 37% of UK players (44% in Spain) choose randomly — the rest select consciously, and persistently, without correcting the habit over years.
How to Prove It for ANY Lottery
You do not need the full likelihood machinery to demonstrate conscious selection in a game you care about. You need only per-draw winner counts at two or more tiers — published by almost every operator — and two tests: the overdispersion test and the cross-tier correlation test. If variance greatly exceeds mean, and tiers are strongly correlated, conscious selection is present. The script below is game-agnostic.
import numpy as np
import pandas as pd
def prove_conscious_selection(winner_counts: dict[int, np.ndarray]) -> dict:
"""Demonstrate conscious selection from per-draw winner counts.
Parameters
----------
winner_counts : dict {tier_label: array of per-draw winner counts}
e.g. {5: Q5, 4: Q4, 3: Q3}, one array per prize tier.
Returns a report with, per tier, the variance/mean ratio (1.0 == pure
random Poisson; >> 1 == conscious selection), plus the cross-tier
correlation matrix (Poisson predicts ~0 everywhere off-diagonal).
"""
report = {"overdispersion": {}, "correlations": None}
cols = {}
for tier, arr in winner_counts.items():
a = np.asarray(arr, dtype=float)
a = a[~np.isnan(a)]
mean, var = a.mean(), a.var()
report["overdispersion"][tier] = {
"mean": mean, "variance": var,
"ratio": var / mean if mean > 0 else float("nan"),
}
cols[tier] = arr
df = pd.DataFrame(cols).dropna()
report["correlations"] = df.corr()
return report
# --- usage on any lottery's history CSV with winner-count columns ---
df = pd.read_csv("history.csv")
rep = prove_conscious_selection({5: df["Q5"], 4: df["Q4"], 3: df["Q3"]})
for tier, s in rep["overdispersion"].items():
print(f"tier {tier}: var/mean = {s['ratio']:.1f} (1.0 == random)")
print(rep["correlations"].round(3))
Applied to Greek Joker lottery (a 5/45 game) the variance/mean ratios came out around 18, 1140, and 38,800 for the 5-, 4-, and 3-match tiers, with cross-tier correlations up to 0.93. Applied to Eurojackpot (5/50) they were about 5, 580, and 20,000, with correlations up to 0.96. In both games the random null is shattered by orders of magnitude — conscious selection is unambiguously present. Any reader can run the same two lines on their own game and see it for themselves.
Flagging Combinations as Popular or Not
Proving the effect exists is one thing; deciding whether a specific combination is popular is another. The right approach is rule-based, because the human biases behind conscious selection are well documented and each one is individually defensible. A combination is flagged AVOID (popular) if it trips any of these named rules:
-
Birthday / calendar bias: all numbers fall in 1–31 — the single largest effect, since players encode dates.
-
Consecutive runs of three or more (12–13–14): visually appealing streaks.
-
Arithmetic progressions with equal gaps (5–10–15–20–25).
-
All numbers sharing a base: all even, all odd, or all multiples of three, five, or ten.
-
Low arithmetic complexity (AC): AC counts how many distinct pairwise gaps a combination has; structured combinations have few. AC ∈ {4,5,6} covers ~96.5% of real draws in both games, so AC below 4 marks the rare, over-chosen structured combinations.
-
Bet-slip shapes: lines, diagonals, full rows/columns, rectangles, L-shapes, horizontal and vertical zig-zags and staircases, and compact blocks. Because slips are printed differently across operators, both grid orientations (e.g. 5×10 and 10×5) are tested.
-
Clustering on the slip: the numbers occupy a small region, measured by tight bounding-box area or perimeter and by low mean pairwise Manhattan or Euclidean distance; plus tight half-grid clustering (all numbers in the leftmost or rightmost third) and full-boundary placement.
The scorer needs no historical data — it encodes the biases directly, so it works for any game and even for combinations never drawn.
Keeping the Flag Honest: How Much Does Each Rule Cut?
A filter is only as trustworthy as its loosest rule. A rule that flags a third of all combinations is not detecting a deliberate human choice — it is a broad bucket that happens to catch random combinations too. So before trusting the flag, we measure, for each rule on its own, what percentage of all combinations it removes (estimated on a large random sample). The principle: every rule should cut a small, comparable slice; any rule that cuts far more than the others is either dropped or retuned until it does.
Measured on the first, untuned version of the rules, four geometric rules stood out as far too loose: the Euclidean-distance cluster rule cut about 17% of Joker combinations (12% of Eurojackpot), the “all numbers in the left half” rule about 11% (9%), and the full-boundary rule about 6% — each several times larger than the sharp shape rules, which cut well under 1%. These broad rules were not measuring deliberate selection so much as loosely-defined position.
The fix was to tighten their thresholds until each cut a slice comparable to the sharp rules: the Euclidean-distance threshold was lowered (from 2.75 to 2.1 average pairwise cells), and the half-grid rules were narrowed from “half the grid” to “the outer third.” The one rule deliberately left broad is the birthday rule: it is the single largest and best-documented effect in the literature, so flagging all 1–31 combinations is justified even though it cuts more than the others. After retuning, the per-rule cut rates are:
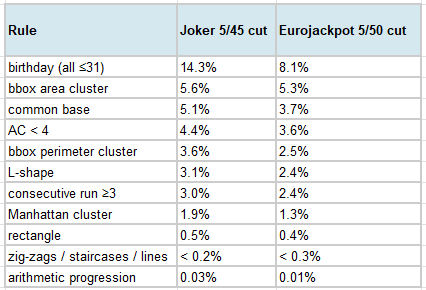
With every rule now cutting a comparable, defensible slice — the birthday rule aside — the combined filter flags about 27% of all Joker combinations and about 20% of Eurojackpot combinations as popular. (Before tightening, the loose rules had inflated these to roughly 45% and 37%, much of it not genuinely “popular.”) A reassuring sanity check is that real random draws trip the rules at essentially the same rate as the whole population — about 26% of historical Joker draws and 20% of Eurojackpot draws are flagged, matching the population rates — confirming the flag is not secretly correlated with the draw itself, only with human-attractive structure.
The Flagging Script
The complete, self-contained script is below. It is parameterised by a game config (pool size, pick count, both grid widths) and the tuned thresholds, and returns for each combination a USE/AVOID flag with reasons. The helper rule_cut_rates reproduces the per-rule analysis above for any game, so you can re-verify and retune the thresholds yourself.
"""
lottery_popularity_flag.py
==========================
ONE-PIECE, self-contained script that flags every lottery combination as
USE or AVOID based on CONSCIOUS-SELECTION popularity rules.
A combination is flagged AVOID (popular -> do NOT play, because you would share
any prize with many other people) if it trips ANY of the rules below:
1. Calendar / birthday bias : all numbers <= 31
2. Consecutive run : 3 or more consecutive numbers (e.g. 12-13-14)
3. Arithmetic progression : equal gaps (e.g. 5-10-15-20-25)
4. Common base : all even, all odd, or all multiples of 3/5/10
5. Low arithmetic complexity : AC < 4 (structurally regular, over-picked)
6. Bet-slip SHAPE : forms a recognisable shape on the slip in EITHER
grid orientation (lines, diagonals, full row/col,
rectangle, L-shape, zig-zags, staircases, compact
block). Tested in both orientations because
operators print slips differently.
Otherwise it is flagged USE (a sensible, low-sharing candidate to actually play).
No third-party imports required beyond the standard library (csv, itertools).
Works for any lotto-style m/n game (Joker 5/45, Eurojackpot 5/50, 6/49, ...).
Author: lottery analysis project. The flag improves expected PAYOUT-IF-YOU-WIN
(less prize-sharing); it does NOT change the probability of winning.
"""
from __future__ import annotations
import csv
from itertools import combinations
from typing import Sequence
# ===========================================================================
# PART A — BET-SLIP GRID & SHAPE DETECTION
# ===========================================================================
def _cells(combo: Sequence[int], ncols: int):
"""Map numbers -> sorted list of (row, col) cells on an `ncols`-wide slip.
Numbers are laid out left-to-right, top-to-bottom: number x sits at
row (x-1)//ncols, column (x-1)%ncols.
"""
return sorted(((x - 1) // ncols, (x - 1) % ncols) for x in combo)
# --- individual shape tests (each takes the (row,col) cell list) ----------- #
def _horizontal_line(cells):
"""All cells share one row -> a straight horizontal line."""
return len({r for r, _ in cells}) == 1
def _vertical_line(cells):
"""All cells share one column -> a straight vertical line."""
return len({c for _, c in cells}) == 1
def _diagonal(cells):
"""All cells on one diagonal: row-col constant (\\) or row+col constant (/)."""
return len({r - c for r, c in cells}) == 1 or len({r + c for r, c in cells}) == 1
def _full_row(cells, ncols, nrows):
"""Cells exactly fill one complete grid row (only when n_pick == ncols)."""
rows = {r for r, _ in cells}
return (len(rows) == 1
and {c for _, c in cells} == set(range(ncols))
and len(cells) == ncols)
def _full_col(cells, ncols, nrows):
"""Cells exactly fill one complete grid column (only when n_pick == nrows)."""
cols = {c for _, c in cells}
return (len(cols) == 1
and {r for r, _ in cells} == set(range(nrows))
and len(cells) == nrows)
def _rectangle(cells):
"""Cells include the four corners of an axis-aligned rectangle (>=4 cells)."""
rs = {r for r, _ in cells}; cs = {c for _, c in cells}
if len(rs) < 2 or len(cs) < 2 or len(cells) < 4:
return False
rmin, rmax, cmin, cmax = min(rs), max(rs), min(cs), max(cs)
corners = {(rmin, cmin), (rmin, cmax), (rmax, cmin), (rmax, cmax)}
return corners.issubset(set(cells))
def _L_shape(cells):
"""An L / corner: one shared row and one shared column meeting at a cell,
together covering all cells, and not a straight line."""
if _horizontal_line(cells) or _vertical_line(cells):
return False
cset = set(cells)
for cr, cc in cells:
on_row = [p for p in cset if p[0] == cr]
on_col = [p for p in cset if p[1] == cc]
if len(on_row) >= 2 and len(on_col) >= 2 and len(on_row) + len(on_col) - 1 == len(cells):
return True
return False
def _zigzag_h(cells):
"""Horizontal zig-zag: distinct columns read left-to-right while the row
bounces between exactly two adjacent rows (a W / M shape)."""
pts = sorted(cells, key=lambda p: (p[1], p[0]))
cols = [c for _, c in pts]; rows = [r for r, _ in pts]
if len(set(cols)) != len(cols) or len(set(rows)) != 2:
return False
d = [rows[i + 1] - rows[i] for i in range(len(rows) - 1)]
return all(x != 0 for x in d) and all((d[i] > 0) != (d[i + 1] > 0) for i in range(len(d) - 1))
def _zigzag_v(cells):
"""Vertical zig-zag: distinct rows read top-to-bottom while the column
bounces between exactly two columns."""
pts = sorted(cells, key=lambda p: (p[0], p[1]))
rows = [r for r, _ in pts]; cols = [c for _, c in pts]
if len(set(rows)) != len(rows) or len(set(cols)) != 2:
return False
d = [cols[i + 1] - cols[i] for i in range(len(cols) - 1)]
return all(x != 0 for x in d) and all((d[i] > 0) != (d[i + 1] > 0) for i in range(len(d) - 1))
def _staircase_h(cells):
"""Horizontal staircase: distinct columns, with the row stepping monotonically
(all steps up, or all steps down) as you read across."""
pts = sorted(cells, key=lambda p: p[1])
cols = [c for _, c in pts]; rows = [r for r, _ in pts]
if len(set(cols)) != len(cols):
return False
d = [rows[i + 1] - rows[i] for i in range(len(rows) - 1)]
return len(d) > 0 and (all(x >= 1 for x in d) or all(x <= -1 for x in d))
def _staircase_v(cells):
"""Vertical staircase: distinct rows, with the column stepping monotonically."""
pts = sorted(cells, key=lambda p: p[0])
rows = [r for r, _ in pts]; cols = [c for _, c in pts]
if len(set(rows)) != len(rows):
return False
d = [cols[i + 1] - cols[i] for i in range(len(cols) - 1)]
return len(d) > 0 and (all(x >= 1 for x in d) or all(x <= -1 for x in d))
def _compact_block(cells, max_area=6):
"""Cells cluster in a small bounding box -> reads as a drawn blob/shape."""
rs = [r for r, _ in cells]; cs = [c for _, c in cells]
return (max(rs) - min(rs) + 1) * (max(cs) - min(cs) + 1) <= max_area
def _all_left(cells, ncols, frac=0.35):
"""All cells in the leftmost `frac` of columns (tight low-side clustering)."""
return all(c < ncols * frac for _, c in cells)
def _all_right(cells, ncols, frac=0.35):
"""All cells in the rightmost `frac` of columns (tight high-side clustering)."""
return all(c >= ncols * (1 - frac) for _, c in cells)
def _boundary(cells, ncols, nrows):
"""All cells sit on the outer border (top/bottom row or left/right column)."""
return all(r == 0 or r == nrows - 1 or c == 0 or c == ncols - 1
for r, c in cells)
def _mean_pairwise_distance(cells, metric):
"""Mean distance over all cell pairs. metric: 'manhattan' or 'euclid'.
A LOW mean pairwise distance means every number sits close to every other on
the slip - i.e. the whole combination occupies a small region (a tight cluster
a human would draw). This is more sensitive than a bounding box because it
reflects how packed the points are, not just their extent.
"""
n = len(cells)
if n < 2:
return 0.0
total = 0.0
for i in range(n):
for j in range(i + 1, n):
dr = cells[i][0] - cells[j][0]
dc = cells[i][1] - cells[j][1]
total += (abs(dr) + abs(dc)) if metric == "manhattan" else (dr * dr + dc * dc) ** 0.5
return total / (n * (n - 1) / 2)
def _bbox_area_perimeter(cells):
"""Bounding-box span area and perimeter of the cells.
Uses the SPAN (max - min) in each axis, so a perfectly straight line has
area 0. Returns (area, perimeter) where:
height = max_row - min_row, width = max_col - min_col,
area = height * width, perimeter = 2 * (height + width).
LOW values mean the numbers are confined to a small rectangle of the slip -
another tight-cluster signal that humans find attractive.
"""
rs = [r for r, _ in cells]; cs = [c for _, c in cells]
h = max(rs) - min(rs)
w = max(cs) - min(cs)
return h * w, 2 * (h + w)
# Shapes used by the flag. Distinctive geometric shapes (lines, diagonals,
# rectangles, L-shapes, zig-zags, staircases, compact blocks) plus, by request,
# half-grid clustering (all_left / all_right), full-boundary, and tight-cluster
# metrics (low mean pairwise Manhattan / Euclidean distance). These last ones
# capture combinations packed into a small region of the slip - another strongly
# human-attractive pattern.
def detect_shapes(combo: Sequence[int], n_pool: int, n_pick: int,
orientations: Sequence[int],
manhattan_max: float = 2.6,
euclid_max: float = 2.1,
bbox_area_max: int = 6,
bbox_perim_max: int = 10,
half_fraction: float = 0.35) -> set:
"""Return the set of distinctive shape names this combo forms in ANY orientation.
Parameters
----------
combo : the combination.
n_pool : size of the number pool (45, 49, 50, ...).
n_pick : how many numbers per ticket (usually 5 or 6).
orientations : column counts to test, e.g. (5, 10) tries 5-wide and 10-wide slips.
manhattan_max: flag 'cluster_manhattan' if mean pairwise Manhattan distance < this.
euclid_max : flag 'cluster_euclid' if mean pairwise Euclidean distance < this.
bbox_area_max: flag 'cluster_bbox_area' if bounding-box span area <= this.
bbox_perim_max: flag 'cluster_bbox_perim' if bounding-box perimeter <= this.
"""
found = set()
for ncols in orientations:
nrows = -(-n_pool // ncols) # ceil division
cells = _cells(combo, ncols)
area, perim = _bbox_area_perimeter(cells)
tests = {
"horizontal_line": _horizontal_line(cells),
"vertical_line": _vertical_line(cells),
"diagonal": _diagonal(cells),
"full_row": _full_row(cells, ncols, nrows),
"full_column": _full_col(cells, ncols, nrows),
"rectangle": _rectangle(cells),
"L_shape": _L_shape(cells),
"zigzag_h": _zigzag_h(cells),
"zigzag_v": _zigzag_v(cells),
"staircase_h": _staircase_h(cells),
"staircase_v": _staircase_v(cells),
"compact_block": _compact_block(cells),
"all_left": _all_left(cells, ncols, half_fraction),
"all_right": _all_right(cells, ncols, half_fraction),
"boundary": _boundary(cells, ncols, nrows),
"cluster_manhattan": _mean_pairwise_distance(cells, "manhattan") < manhattan_max,
"cluster_euclid": _mean_pairwise_distance(cells, "euclid") < euclid_max,
"cluster_bbox_area": area <= bbox_area_max,
"cluster_bbox_perim": perim <= bbox_perim_max,
}
found.update(name for name, hit in tests.items() if hit)
return found
# ===========================================================================
# PART B — NUMERIC POPULARITY RULES
# ===========================================================================
def arithmetic_complexity(combo: Sequence[int]) -> int:
"""AC = (number of DISTINCT positive pairwise differences) - (n_pick - 1).
Few distinct differences => structurally regular (progressions, repeated
gaps) => low AC => over-picked by players. Empirically AC in {4,5,6} covers
~96.5% of real draws in Joker (5/45) and Eurojackpot (5/50), so AC < 4
marks the rare, structured, popular combinations.
"""
c = sorted(int(x) for x in combo)
diffs = {c[j] - c[i] for i in range(len(c)) for j in range(i + 1, len(c))}
return len(diffs) - (len(c) - 1)
def longest_run(combo: Sequence[int]) -> int:
"""Length of the longest run of consecutive integers in the combination."""
c = sorted(int(x) for x in combo)
best = run = 1
for i in range(1, len(c)):
run = run + 1 if c[i] - c[i - 1] == 1 else 1
best = max(best, run)
return best
# ===========================================================================
# PART C — THE COMBINED FLAG
# ===========================================================================
def flag_combo(combo: Sequence[int],
n_pool: int = 50,
n_pick: int = 5,
orientations: Sequence[int] = (5, 10),
calendar_max: int = 31,
min_ac: int = 4,
max_run: int = 2,
exclude_shapes: Sequence[str] = ("cluster_euclid", "all_left",
"all_right", "boundary")) -> dict:
"""Flag one combination as USE or AVOID using ALL popularity rules.
Returns
-------
dict with:
avoid : bool -- True => popular => do NOT play
reasons : list[str] -- every rule tripped (empty if USE)
ac : int -- arithmetic complexity (kept for convenience)
Notes
-----
The combination is AVOID if it trips ANY rule. Each rule is an independently
documented conscious-selection bias, so every flag is individually justifiable.
"""
c = sorted(int(x) for x in combo)
reasons = []
# Rule 1 - calendar / birthday bias
if all(x <= calendar_max for x in c):
reasons.append(f"all<= {calendar_max} (birthday)")
# Rule 2 - consecutive run of 3+
if longest_run(c) > max_run:
reasons.append(f"consecutive_run>{max_run}")
# Rule 3 - arithmetic progression (equal gaps)
diffs = [c[i + 1] - c[i] for i in range(len(c) - 1)]
if len(set(diffs)) == 1:
reasons.append("arithmetic_progression")
# Rule 4 - common base (all even / odd / multiples of 3,5,10)
if any(all(x % b == 0 for x in c) for b in (2, 3, 5, 10)):
reasons.append("common_base")
elif all(x % 2 == 1 for x in c): # all odd (not caught by %2==0 above)
reasons.append("common_base")
# Rule 5 - low arithmetic complexity
ac = arithmetic_complexity(c)
if ac < min_ac:
reasons.append(f"AC<{min_ac}")
# Rule 6 - distinctive bet-slip shape in either orientation.
# By default the loosest rules (broad Euclidean cluster, half-grid, full
# boundary) are excluded so every flag rests on a sharp, well-documented
# pattern; pass exclude_shapes=() to use the full set.
shapes = detect_shapes(c, n_pool, n_pick, orientations)
for sh in sorted(shapes - set(exclude_shapes)):
reasons.append(f"shape:{sh}")
return {"avoid": len(reasons) > 0, "reasons": reasons, "ac": ac}
def flag_all(n_pool: int, n_pick: int, orientations: Sequence[int],
out_path: str, calendar_max: int = 31,
min_ac: int = 4, max_run: int = 2,
exclude_shapes: Sequence[str] = ("cluster_euclid", "all_left",
"all_right", "boundary")) -> tuple:
"""Flag EVERY combination of the game and write a CSV of USE/AVOID.
Output columns: n1..n_pick, AC, flag.
Returns (total_combos, n_avoid).
"""
total = avoid = 0
with open(out_path, "w", newline="") as f:
w = csv.writer(f)
w.writerow([f"n{i}" for i in range(1, n_pick + 1)] + ["AC", "flag"])
for combo in combinations(range(1, n_pool + 1), n_pick):
res = flag_combo(combo, n_pool, n_pick, orientations,
calendar_max, min_ac, max_run, exclude_shapes)
total += 1
if res["avoid"]:
avoid += 1
w.writerow([*combo, res["ac"], "AVOID" if res["avoid"] else "USE"])
return total, avoid
# ===========================================================================
# DEMO / SELF-TEST
# ===========================================================================
def rule_cut_rates(n_pool, n_pick, orientations, n_sample=120000, seed=0):
"""Estimate the percentage of all combinations each rule cuts, on its own.
Samples random combinations and reports, per rule, the fraction it flags.
Use this to keep only the TIGHTEST rules, or to retune loose thresholds so
every rule cuts a comparably small, defensible slice.
"""
import random
from collections import Counter
rng = random.Random(seed)
samp = [tuple(sorted(rng.sample(range(1, n_pool + 1), n_pick))) for _ in range(n_sample)]
cnt = Counter()
for c in samp:
res = flag_combo(c, n_pool, n_pick, orientations)
for r in res["reasons"]:
key = r.split(" ")[0] # normalise "all<= 31 (birthday)" etc.
cnt[key] += 1
return {k: 100.0 * v / n_sample for k, v in
sorted(cnt.items(), key=lambda kv: -kv[1])}
if __name__ == "__main__":
print("Self-test on sample combinations (Eurojackpot 5/50, orientations 5 & 10):\n")
samples = [
(1, 2, 3, 4, 5), # line / run / AP / birthday / low AC
(1, 11, 21, 31, 41), # vertical line / AP / column
(5, 14, 23, 32, 41), # diagonal / staircase / AP
(1, 5, 46, 50, 25), # rectangle (corners + centre)
(2, 4, 6, 8, 10), # all even / line
(8, 19, 33, 41, 44), # scattered -> USE
(3, 11, 28, 37, 49), # scattered -> USE
]
for s in samples:
r = flag_combo(s, n_pool=50, n_pick=5, orientations=(5, 10))
tag = "AVOID" if r["avoid"] else "USE"
print(f" {str(s):22s} {tag:5s} AC={r['ac']} {', '.join(r['reasons']) or '-'}")
# Example: flag whole games (uncomment to run; each writes a CSV)
# t, a = flag_all(45, 5, (9, 5), "joker_flags.csv") # Greek Joker
# print(f"\nJoker 5/45: {a}/{t} AVOID ({100*a/t:.1f}%)")
# t, a = flag_all(50, 5, (5, 10), "eurojackpot_flags.csv") # Eurojackpot
# print(f"Eurojackpot 5/50: {a}/{t} AVOID ({100*a/t:.1f}%)")
Does the Flag Capture Real Behaviour?
A flag built from intuition is only worth as much as its validation. The test: for each historical draw, score how popular its winning combination was, then check whether popular winning combinations attracted more winners than unpopular ones (after adjusting for sales, estimated from a near-random low tier). A positive, significant rank correlation means the flag is measuring genuine crowd behaviour.
The result depends on sample size and player volume. For Greek Joker, with fewer players and 3,291 draws, the correlation was weak and not significant — the signal was real but too faint to measure cleanly. For Eurojackpot, with its vast multinational player base and far higher winner counts, the correlation was strong and highly significant (Spearman rho ≈ 0.23, p ≈ 3×10⁻¹³), in the correct direction: popular winning combinations drew measurably more co-winners. On Eurojackpot, then, the flag is not merely literature-backed — it is empirically validated on the game’s own data.
How to Exploit the Flag
The exploitation is precise, and so is its limit. Avoiding popular combinations does not raise your probability of winning — a random draw is exactly as likely to be a birthday combination as a scattered one. What it raises is your expected payout conditional on winning, because you are far less likely to share the prize. Three concrete ways to use the flag:
First, as a filter on any play set. Whatever combinations you would otherwise play, drop the ones flagged AVOID and keep only USE combinations. You give up nothing in win probability and reduce expected prize-sharing on the tiers where popular clustering is strongest.
Second, in combination with a covering wheel. If you build a guaranteed-coverage wheel, relabel or select its tickets so they fall in the USE set. The guarantee is unaffected by which numbers fill it, so this is a free improvement: same coverage, lower sharing. Check my other article on Medium for creating such coverings.
Third, as a timing lens. The benefit of unpopular combinations is largest exactly when many people play — large rolled-over jackpots that attract casual, birthday-driven players. Choosing scattered, high-number, pattern-free combinations at those moments maximises the share you would keep.
The honest boundary, which belongs in every responsible treatment: this is an edge over other players, never over the house. Eurojackpot and Joker both return only about half of stakes as prizes. Avoiding popular combinations improves the value of a winning ticket but cannot make the game profitable in expectation. It is a way to lose less to fellow players when luck does strike — not a way to beat the draw.